Amazon Reviews Analysis: Parsing, Sentiment Analysis, and Clustering
Project Overview
This project is a data science and natural language processing (NLP) pipeline that extracts, processes, and analyzes Amazon reviews for specific products. The aim is to provide insights into customer sentiments, product strengths, and weaknesses, and make product comparisons more straightforward. This system uses a combination of web scraping, NLP techniques, and machine learning models to parse, cluster, and evaluate review sentiments with detailed statistical analysis.
Technical Workflow
The analysis pipeline for Amazon reviews involves several key stages:
- Data Collection: Using Selenium to automate browser actions, the system scrapes review data for specified products. Each review includes metadata such as review ID, rating, date, and review text.
- Text Preprocessing: The reviews are cleaned and tokenized by removing unnecessary characters, single characters, and extra spaces. Stop words are removed, and lemmatization is applied to reduce words to their root forms.
- Sentiment Analysis: Using the VADER sentiment analysis tool, the system computes compound sentiment scores for each review. Reviews are classified as positive, negative, or neutral based on predefined thresholds for compound scores.
- Clustering and Topic Modeling: K-means clustering and Principal Component Analysis (PCA) are used to identify distinct clusters of reviews based on term frequency-inverse document frequency (TF-IDF) vectors, allowing for exploration of different review themes.
- OpenAI GPT Integration: Summaries of clusters and major sentiment trends are generated using OpenAI's GPT-3/4 API. This provides an easily interpretable output, summarizing the key positive and negative points for each product.
Data Collection
Using the Selenium WebDriver, the script automates browser actions to scrape product reviews from Amazon. Each review's metadata is extracted, including:
- Review ID: Unique identifier for each review.
- Rating: Rating score (1-5 stars) for sentiment weighting.
- Date: Timestamp for tracking temporal trends in reviews.
- Verified Purchase: Boolean indicating verified purchase status.
- Review Text: Main content of the review.
Text Preprocessing
The raw review texts are processed using Python’s re and nltk libraries for NLP preprocessing. Steps include:
- Tokenization: Splitting reviews into individual words.
- Stopword Removal: Filtering out common stopwords.
- Lemmatization: Reducing words to their base forms.
- Special Character Removal: Removing punctuation and non-alphanumeric characters.
This ensures that the text is ready for analysis and minimizes noise.
Sentiment Analysis
Using the VADER sentiment analyzer, each review is scored for positive, neutral, and negative sentiment components. A compound score is computed, which classifies reviews as:
- Positive: If the positive score is dominant.
- Neutral: If neither positive nor negative dominates.
- Negative: If the negative score is dominant.
Additionally, the compound score is used to gauge overall sentiment intensity and polarity for further analysis.
Clustering and Topic Modeling
TF-IDF vectors are generated for each review, and K-means clustering is applied to group reviews based on thematic similarities. Principal Component Analysis (PCA) is then used for dimensionality reduction and visual representation.
Steps:
- TF-IDF Vectorization: Transforming review text into numerical form.
- K-Means Clustering: Grouping reviews into clusters based on content similarity.
- PCA: Reducing dimensions for visualization and highlighting main themes.
GPT Integration for Summarization
Using OpenAI’s GPT-3/4 API, the system summarizes each cluster of reviews, extracting top pros and cons. This step generates a readable summary of key themes in customer feedback, which helps in decision-making and understanding consumer preferences.
Results and Visualizations
The final outputs include:
- Sentiment Distribution: Histograms showing the distribution of positive, negative, and neutral reviews.
- Cluster Analysis: Visuals and word clouds for each cluster, indicating dominant themes.
- Time-Series Analysis: Plots showing trends in review sentiment over time.
- GPT Summaries: Summarized key insights from each cluster using GPT-3/4.
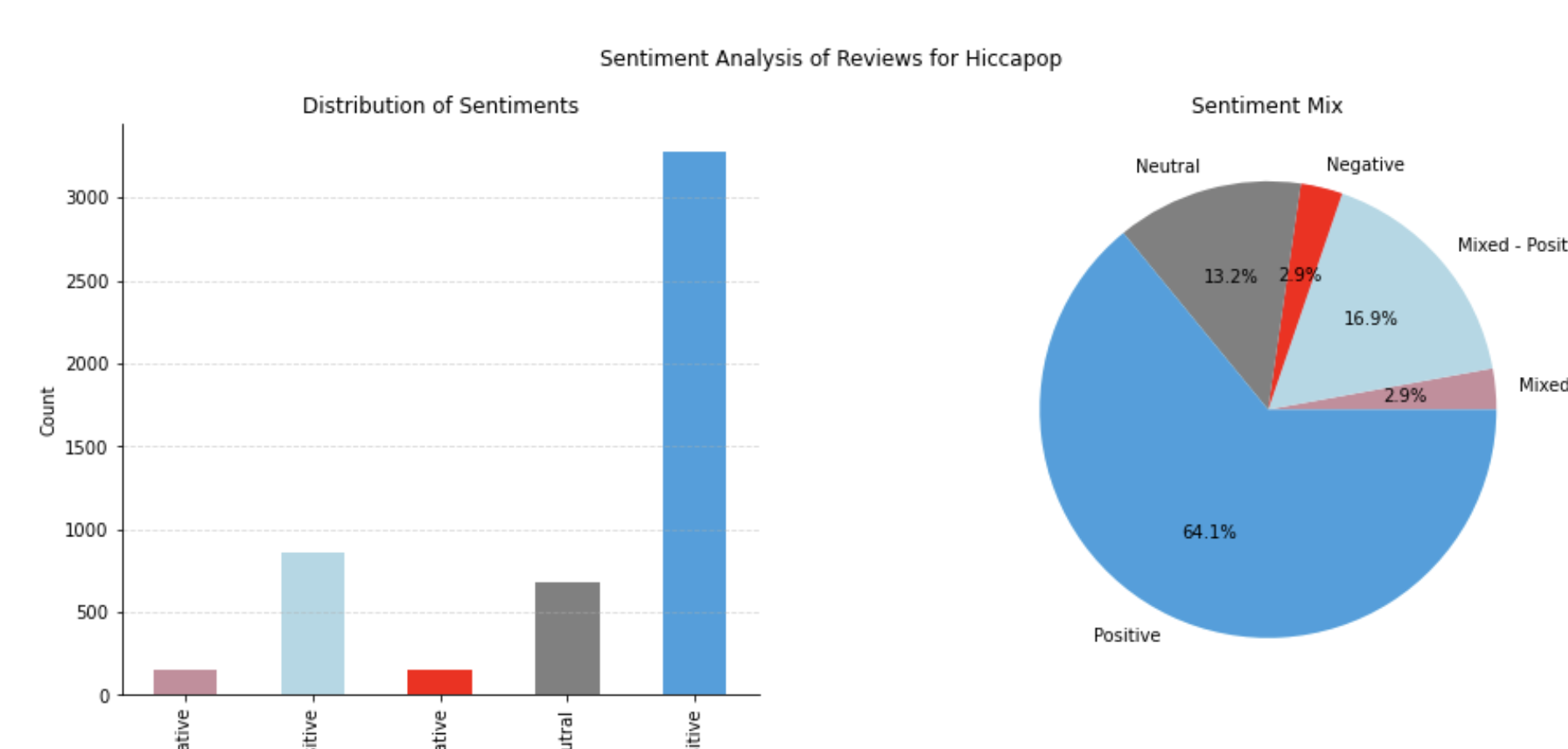
Case Study: Hiccapop Product Reviews
The Hiccapop travel booster seat and related baby products were analyzed using the sentiment analysis and clustering techniques applied in this project. Key differences emerged between Hiccapop and a competitor’s product reviews, providing insight into customer preferences and areas for improvement.
Positive Sentiment Summary for Hiccapop
Hiccapop products received positive feedback for their:
- Lightweight and compact design, making them ideal for travel and outdoor use (e.g., camping, beach trips).
- Sturdy build and quality fabric, which enhances durability and ease of cleaning.
- Convenient features, such as easy assembly and adjustable straps, which fit well with various seating needs.
Hiccapop Product
Comparative Review Highlights
Compared to a similar product, Hiccapop was praised for its:
- Versatility across multiple use cases (e.g., travel, restaurant use, and home).
- Thoughtful design elements, like the inclusion of a carry bag, which adds to its portability and convenience.
While both products received positive reviews, Hiccapop’s compact design, ease of use, and family-friendly features resonated particularly well with parents looking for reliable travel solutions for young children.
Conclusion
This project successfully demonstrates the use of advanced data science techniques for e-commerce analysis. The combination of NLP, sentiment analysis, clustering, and GPT-based summarization provides a comprehensive tool for analyzing customer sentiment on Amazon. The insights gained from this project can assist businesses in identifying product strengths and weaknesses, tailoring marketing strategies, and enhancing product features based on customer feedback.